
Jarret Geenen, Assistant Professor, Radboud University, Centre for Language Studies
Tui Matelau-Doherty, Senior Lecturer, Unitec Institute of Technology
Sigrid Norris, Professor, Auckland University of Technology, Multimodal Research Centre
Les sciences de la communication et du langage ont décidément pris un tournant multimodal et de nombreux travaux, dans ces domaines auparavant dominés par la langue, s’intéressent désormais à la communication non verbale dans l’interaction sociale. Bien que ces recherches se soient avérées être fructueuses sur les plans empirique et théorique, une difficulté s’ajoute à cette question déjà compliquée : les pratiques de transcription et le processus d’interprétation et de représentation accompagnant lesdites pratiques. Dans cet article, nous examinons et défendons un cadre méthodologique qui fournit des outils analytiques et un protocole de transcription pour la génération de transcriptions visuelles. Selon nous, la transcription visuelle est beaucoup plus conforme à l’éthos multimodal et nous détaillons la méthode en l’appliquant à des données issues d’un travail d’équipe et d’investigation qui s’est intéressé aux interactions dyadiques par vidéoconférence. L’accent mis sur l’action et la méthode de transcription qui l’accompagne révèlent des distributions complexes et fluctuantes de l’attention et de la conscience interactive. Les actions non verbales révèlent des contributions à la tâche à accomplir qui ne sont pas réalisées dans le discours et l’analyse détaille un flux complexe d’orientations attentionnelles qui sont réalisées par des moyens non verbaux.
Mots-clés : Transcription visuelle, Analyse multimodale, Interaction, Vidéoconférence
The communication and language sciences have decidedly taken a multimodal turn and a proliferation of work in previously language-dominated fields is focusing on the contribution of non-verbal communicative modes in social interaction. While this has proven empirically and theoretically fruitful, it throws an additional kink in an already complicated issue: transcription practices and the interpretive and representational process accompanying said practices. In this article, we review and champion a methodological framework that provides analytical tools and a transcription protocol for the generation of visual transcripts. Visual transcription, we contest, is far more congruent with the multimodal ethos and we both detail the method while applying it to a data segment from a larger project investigation teamwork and collaborative problem-solving in dyadic videoconferencing interactions. The analytical focus on action coupled with the accompanying transcription method reveals complex and fluctuating distributions of attention and interactional awareness. Non-verbal actions reveal contributions to the task at hand which are not realized in talk and the analysis details an intricate ebb and flow of attentional orientations which are realized through non-verbal means.
Keywords : Visual-transcription, Multimodal analysis, Interaction, Videoconferencing










In this article, we present visual transcription conventions (Norris, 2004, 2011, 2019) with an example of teamwork via videoconferencing. The transcription conventions are part and parcel of the larger multimodal social theoretical framework, Multimodal (Inter)action Analysis (MIA; Norris, 2020). MIA, much like the foundational method, mediated discourse analysis (Scollon, 1998, 2001), takes the mediated action as its basic unit of analysis. With this unit of analysis, the social actor is always tied to the mediational means that are used when performing the mediated action, so that neither a social actor nor mediational means can ever be analyzed alone. Thus, mediation is the glue between social actor(s) and mediational means. This basic unit was taken up from mediated discourse analysis, however, the basic unit is also where MIA diverges from mediated discourse analysis: MIA differentiates between various kinds of mediated actions from lower-level mediated actions and higher-level mediated actions to frozen mediated actions. Lower-level mediated actions are the smallest pragmatic meaning units of a communicative mode, where a mode is defined as a system of mediated action (Norris, 2013). As we will see below, the lower-level action is the unit on which the transcription conventions are based. Higher-level actions are the coming together of a multitude of chains of lower-level mediated actions at the same time as higher-level mediated actions produce these chains. Thus, neither lower- not higher-level mediated actions are prior. Below, we discuss the multimodal analysis of one higher-level mediated action. Frozen mediated actions are those actions that are frozen in the environment or in objects within. Below, we see frozen mediated actions when we speak of the mode of layout. We will not be discussing the multimodal social theoretical framework, MIA in complete detail. Our aim is to explicate the visual transcription conventions, how they are used, and what can be learned by using this visual method of transcription. As a result, we will not provide in depth discussion about the theoretical grounding of the methodological framework (Norris, 2020).
The data segment which is the basis of the analysis herein comes from an experimental teamwork study of dyads working on tasks via videoconferencing technology. In this article, we look at one higher-level action during the first task given to all pairs. The pairs were seated in different rooms in front of a computer or laptop and then provided with an address of a hotel in a city that neither of them had ever visited. This hotel was ostensibly where they would be travelling to on a business trip. Their task now was to find a place to have dinner together. The study of dyadic videoconferencing interactions resulted from research questions that were unanswered during our previous ethnographic study of families with young children interacting via videoconferencing technology.
In what follows, we provide a brief discussion of the central issues surrounding transcription in the language and communication sciences while providing some background on the multimodal research which has been completed in the domain of videoconferencing. We attempt to provide some brief background on the central theoretical tenants of MIA (Norris 2004, 2011, 2019, 2020) while detailing the method and protocol of transcription and analysis. Based on the analysis of a data segment from the study of dyadic computer mediated teamwork, we first argue that visual transcription and a multimodal approach are imperative when looking at computer-mediated social interaction. Additionally, we argue that when investigating communicative action rather than simply conversation, we see that linguistic phenomena alone cannot account for the distribution of focused attention and discuss the ebbs and flows of attentional divergence in collaborative teamwork.
In the past two decades, the affordability and portability of high-quality audio-video recording devices have contributed to a proliferation of their use in the generation of data sets in the social sciences and humanities. In fields like Linguistics and Communication Studies where real-time human communicative activity is the empirical focus, the use of video cameras has had considerable repercussions. Not only did the employment of digital video cameras coincide with a multimodal turn in the traditionally language-centered areas like Discourse Analysis, Conversation Analysis and Interactional Sociolinguistics, it also forced a serious reconsideration of practices of data transcription and representation. The way researchers turn the material qualities of talk into a static textual representation has always been subject to debate, critical consideration and reflection. However, video-graphic data sets have further complicated this issue. It has again forced researchers to critically consider how transcription practices are interrelated with theory, ideology and analysis while simultaneously exercising explicit self-reflexivity in efforts to make transparent how these interrelationships affect the findings of empirical endeavors.
Transcription has long been an issue of central consideration for researchers in language-oriented empirical domains and for good reason. Spoken language as it occurs in the real world has a momentary and quickly fleeting materiality. It is a phenomenon that is very difficult to investigate in a natural domain without some manner of capturing the material for further investigation. Recording is therefore essential to ensure some degree of permanency of the empirical subject so as to allow more thorough examination. Observations and recordings of the actual phenomenon are important but equally important are means for providing representations about the thing of interest. For language, this is usually referred to as the practice of transcription whereby the linguist makes a selection regarding what components of the material phenomenon are important and finds a suitable form of representation for those components.
Following Green et al. (1997) and Bucholtz (2000), we consider transcription practices as involving at least two interrelated processes: interpretive processes and representational processes. Bucholtz (2000) explains that “[a]t the interpretive level, the central issue is what is transcribed; at the representational level the central issue is how it is transcribed” (p. 1441). The interpretive and representational processes of transcription practices have considerable consequences insofar as they are implicitly telling of much more than might seem on the surface. The analyst is in many ways forced to make decisions during interpretive and representational processes. In doing so, much is revealed about their own empirical ethos, the socio-cultural value of particular categories and classifications in their given field and even what precise phenomenological processes are determined to be of empirical value and academic or institutional salience. The transcription practices of different fields are decisively telling insofar as the salience of different features of the phenomenological ‘reality’ on record and the representational practices whereby they are realized or ‘transduced’ (Bezemer and Mavers, 2011) into another mode speaks to the dominant ethos, ideologies, values and norms in respective subsidiary fields.
The degree to which transcripts and transcription practices are revealing of various things they are equally concealing of many others. In some cases, the things which may be concealed in any transcript may be empirically justified on the grounds that the researcher is not primarily concerned with that aspect of the phenomenon. This may be empirically acceptable within subsidiary disciplines which prioritize a specific component of language or a particular mode of interactional exchange (language for instance). However, for fields more broadly concerned with the entirety of the communicative process, that which is concealed in transcription becomes problematic as its potential value in the communicative process is muted a priori.
In the study of interaction analysis, video-recorded data are considered essential due to the focus on naturally occurring interaction (Miller, 2018). Therefore, the challenge of visual transcription is experienced by researchers within multiple interaction analysis approaches: Multimodal Conversation Analysis, Social Semiotics, Systemic Functional Multimodal Discourse Analysis, Multimodal Critical Discourse Analysis, and many others. Bezemer and Mavers (2011) summarize a selection of approaches to visual transcripts highlighting the difference in the use of images, for instance, selecting one or several video stills to create a sense of inclusion or using drawings to make a transcript seem more real.
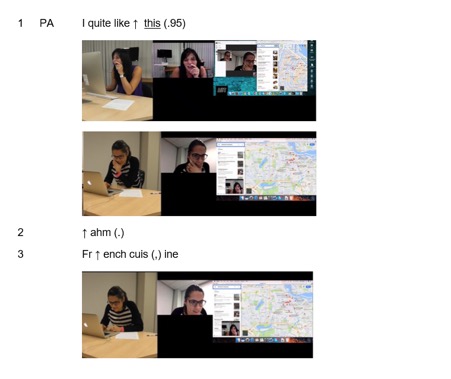
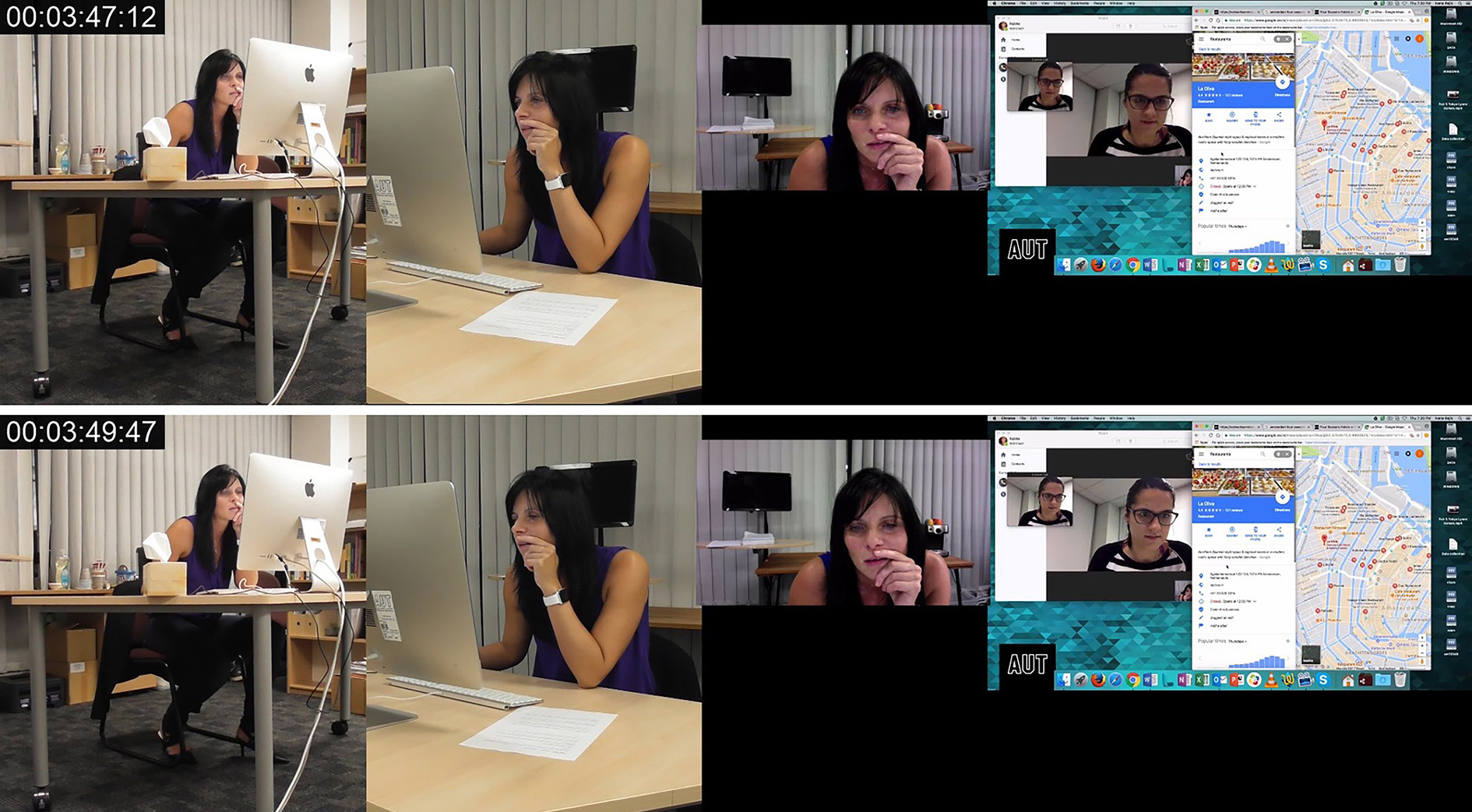
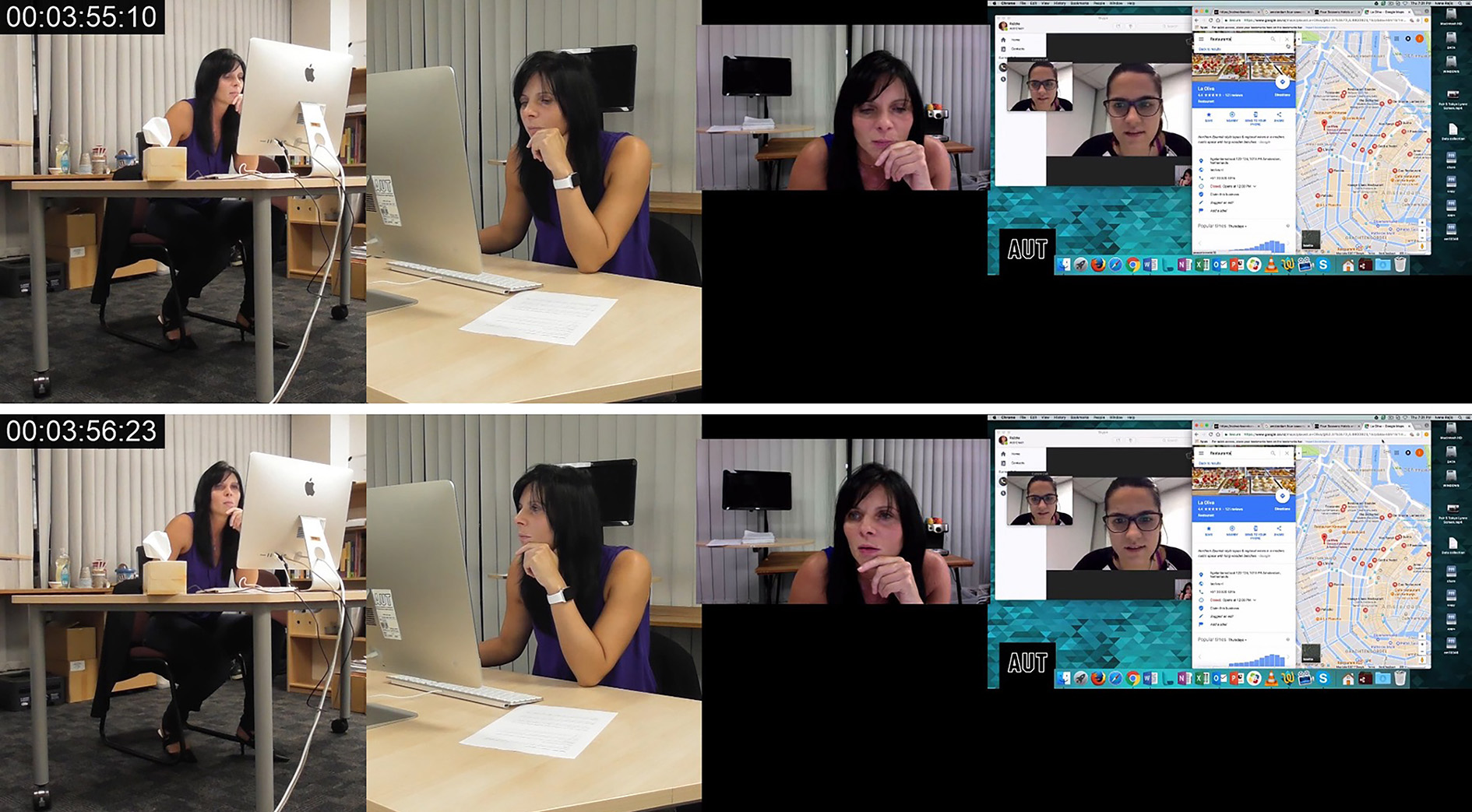
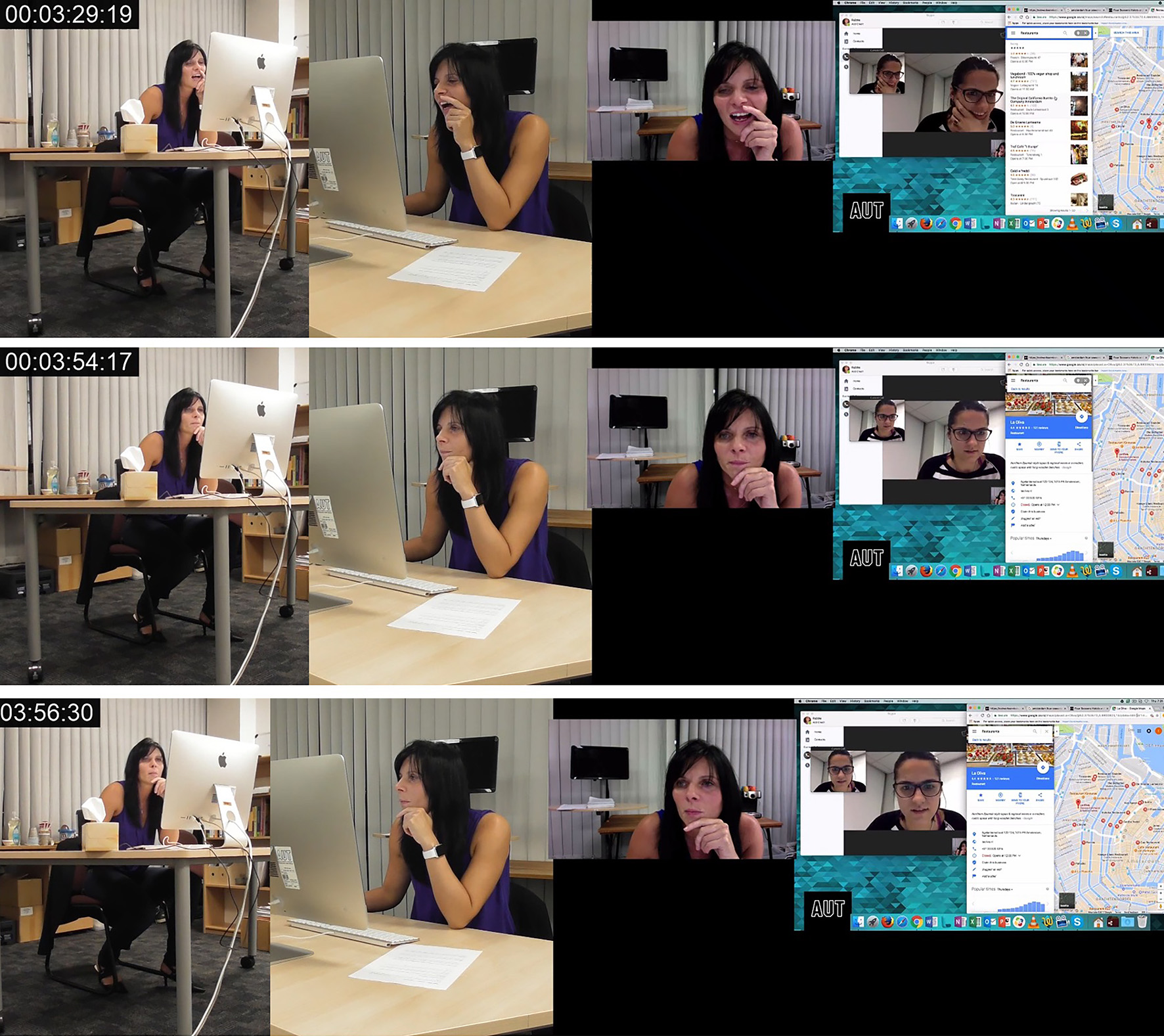
To illustrate key differences in the way that visual transcripts are produced, we briefly introduce the transcription conventions of one other prominent multimodal approach, Multimodal Conversation Analysis (MCA). Multimodal Conversation Analysts utilize audio and video recordings of authentically occurring activity in order to analyze the temporal and sequential arrangement of the activity, by the participants (Mondada, 2012). However, even when multimodal features are incorporated into the analysis, the assumption is that speech shapes the use of the other multimodal features (Sidnell, 2012) which is visible in the initial approach to data collection “although we may have some ideas about where to look, we are interested in whatever details of the talk are relevant to the participants” (p. 87). Furthermore, the significance of language within MCA is seen in the transcription conventions. Jefferson’s (1984) transcription conventions are used for transcribing speech. and the key features of these transcription conventions are, speaker identification, accurate representation of speech and temporal and sequential features (Hepburn and Bolden, 2012). Punctuation, symbols and formatting are used to indicate multimodal features such as intonation, volume, pitch, tempo and so forth. Transcriptionist comments, visual representations and video frame grabs are used to portray other multimodal features such as gaze, body movement, gesture and so forth. Following Jefferson’s (1984) transcription conventions for speech and Bolden’s (2003) transcription conventions that include video grabs, Image 1 depicts an excerpt of an MCA transcript for the data segment being analyzed in this article.
Image 1 - MCA transcription example. Finding La Oliva, 2019
© AUT Multimodal Research Center
The transcription conventions depicted in Image 1 limit the focus to language and although multimodal features are included in the video stills that depict shifts in posture or gesture, language maintains primacy.
While a complete review is beyond the scope herein, many researchers have employed various techniques in an attempt to ‘visualize’ specific non-verbal behavior. Circles including arrows have been used to indicate gaze direction and rough sketches indicating portions of a gestural sequence have proven useful to provide the reader with some idea of the material configuration of the gesture in space. However, the primary issue with these forms of representation is similar to the problematic nature of spoken language-only transcripts. The concentrated focus on a singular mode in transcription and analysis allocates potentially undue salience to that communicative mode in interaction. As detailed in the section entitled Visual Transcription Methods, an initial focus on a single mode in isolation is methodologically useful but only in order to dissect the highly complex multimodal actions to then develop transcripts that demonstrate the connections between the various modes as used in particular interactions. Thus, while for analytical purposes initial minute dissection is needed, it is paramount to always maintaining an analytical orientation toward the interrelationships between communicative modes.
In a methodological departure, Norris (2004, 2011, 2019, 2020) champions a transcription and analysis process which results in fully visual transcripts of the social interaction under investigation. MIA generates visual transcripts which feature series of time-stamped screen grabs of the video data. The frames are chronologically arranged to facilitate a moment-to-moment representation of the interaction itself. Importantly, the sequences of frames are manually produced in the analytical process and feature the unfolding of non-verbal and verbal communicative actions in situ. The representation of concrete communicative actions is central and this necessitates the use of time-stamps. Sequences of frames taken at temporal intervals fail to capture the actual unfolding of communicative action in interaction. While communicative behavior can be considered rhythmic to a degree, it is not rhythmic in a temporally predetermined manner. The focus on concrete actions of a communicative nature ensures the phenomenological interest remains the focus of the sequenced frames. Using the lower-level mediated action as the unit of analysis enables the systematic production of visual transcripts. Although each mode has different structures and materiality, as the smallest pragmatic meaning unit, the lower-level mediated action is the ideal unit to use in transcription as it ensures replicability (Norris, 2020). For example, regardless whether two researchers define gesture differently, by transcribing the lower-level mediated action, they will produce the same transcript (Norris, 2019).
MIA has been fruitfully applied to various forms of social interaction but as communication is increasingly mediated by complex technological tools, forms of visual transcription become essential. Pictorial or diagrammatic representation may be acceptable with a dyad speaking face-to-face, however, what is concealed in technologically mediated interactions is far too great to warrant such practices. During videoconferencing interactions, what social actors do, communicate and respond to involves websites, personal files, things in the material surround and multiple dialogue boxes or tabs that may be attended to simultaneously. As these computer and cell phone mediated interactions have been on the rise, so too has academic interest in the structural and material nature of these interactions.
Norris and Pirini’s (2016) investigation of dyadic teamwork while completing a garden-based planting puzzle via video conferencing highlights the importance of what may be happening out of the direct frame. Participants were required to troubleshoot complex horticultural issues while collaboratively planning a garden. Using multiple camera angles of individual interlocutors in addition to screen recording software, their analysis reveals that language does not always play a superordinate communicative role in the expression of knowledge states, the communication of knowledge and in disagreements. Instead, the authors show how these communicative practices are always and irreducibly multimodal and indeed, linguistic communicative actions about knowledge can lag temporally, far behind this expression through other non-verbal modes.
Everyday communicative practices like communicating and accepting knowledge, coordinating the distribution of collective attention and even the expression of disagreement have been primarily approached as though they are accomplished through spoken language (Holmes and Marra, 2004; Heritage, 2012; Marra, 2012; Morek, 2015). Norris and Pirini (2016), however show that these communicative practices involve complex multimodal ensembles of mediated action involving gaze, posture, gesture and even object handling. These communicative practices are not just performed through multimodal ensembles which include non-verbal modes of communication, sometimes spoken language is completely absent. They show that knowledge states are expressed distinctly by alterations in posture during a videoconferencing session; alterations, which other interlocutors may (or may not) be aware of due to the fragmented audio-video ecology. While not the empirical focus, the insight is made possible by the multiple camera perspectives and multimodal visual transcription. The data of the non-verbal communicative actions would not be available if employing less detailed recording and transcription methods. Visual transcription has also facilitated insights into the structure and unfolding of various communicative actions during videoconferencing which sometimes involve no language at all. Geenen (2017) analyzes one such practice where novice language users communicate with distant family members via videoconferencing.
Previous work on familial videoconferencing interactions employing post-hoc semi-structured evaluative interviews suggests that individuals qualitatively prefer videoconferencing to traditional telephony (Aguilla, 2012). People tend to feel a degree of ‘togetherness’ that was superior to that of the traditional voice call. Visual access to both interlocutors and to physical space most likely play a role in these evaluations but Geenen (2017) argues that it is precisely the potential for the multimodal production of identity elements made possible by videoconferencing that may explain the comparatively positive evaluations. Based on a multimodal interaction analysis (Norris 2004, 2019; Geenen and Pirini 2020) of long-distance familial videoconferencing, Geenen argues that the parentally facilitated interactive practice of showing and sometimes talking about physical objects or entities in the physical surround allows young children to semi-autonomously produce identity elements in real-time which may not be possible through the medium of traditional telephony. The practice of showing and sometimes telling is thus a collaboratively produced interactive practice wherein children who lack the linguistic maturity to explain likes, dislikes, interests, affinities or physical skills, can more autonomously show these things in real-time. The practice of showing physical objects, entities or skills to overseas familial interlocutors is a practice made possible by visual access and videoconferencing technology and facilitates the first-hand production of identity elements not just through the use of verbal language, but through complex multimodal ensembles.
While Geenen (2017) acknowledges this practice as ‘collaborative’, the precise nature of this multiparty collaboration is not detailed in any length. Specifically, contributions from other interlocutors who may not be directly visible are not detailed. Geenen (2018) takes this up elsewhere arguing that constantly changing participation frameworks and parental facilitation off-screen may contribute to certain forms of pragmatic development for younger interlocutors. Multiparty interactions mediated by videoconferencing technologies create challenges for budding conversationalists who are in the early stages of acquiring communicative competence. There are unique attentional demands, certain ambiguities about who is being addressed, who should take the lead and who is responsible for various topics, comments and closures. Geenen (2018) argues however, that the fluidity with which interlocutors enter and exit the interaction creates opportunities for younger interlocutors to introduce ‘new’ topics.
While topic introduction in social interaction has been traditionally approached by looking at the use of spoken language, Geenen (2018) argues that topic introduction can occur through the presentation of physical objects. Additionally, topic introduction is a collaborative phenomenon and one recurrence of a topic introduction suggests that children are learning not only what topics are considered appropriate to introduce with certain social actors, but also, how to introduce said topics. Through the analysis of multimodal transcripts depicting two higher-level actions produced within one family video conference, Geenen (2018) highlights the importance of non-verbal communicative modes to the teaching and learning of higher-order socio-pragmatic aptitudes, such as topic introduction. The direct congruence and subtle variations in agency, autonomy, participant framework and solicitation suggest that the younger social actor preliminarily learned not just that a particular topic was relevant but also how to introduce the topic.
MIA (Norris, 2004, 2020) is a multimodal social theoretical framework that allows the analyst to holistically examine human actions and interactions from micro to meso and macro levels. Theoretically founded upon mediated discourse analysis, the primary unit of analysis remains the mediated action, which is defined as social actor(s) acting with or through mediational means or cultural tools (Wertsch, 1998; Scollon, 1998, 2001). However, in MIA, the mediated action is refined and theorized on different levels, namely lower-level and higher-level(s) of action. The lower-level mediated action is defined as the smallest pragmatic meaning unit of a mode. A mode in MIA is defined as a system of mediated actions (Norris, 2013). In this way, a lower-level mediated action is the concrete instantiation of an action (such as a postural shift), while the abstracted level of the concrete lower-level mediated action is the mode of posture (Norris, 2020). Thus, the lower-level mediated action is always the smallest action that is visible/audible by other social actors such as a social actor moving the body from sitting back in a chair forward or a social actor say uhuh. A higher-level mediated action is defined as the coming together of a multitude of chains of lower-level mediated actions and they have socio-culturally identifiable and constituted beginnings and endings. On the one hand, lower-level mediated actions (such as hand movements, gaze shifts or utterances) build the higher-level mediated action (such trying to find a restaurant online). But on the other hand, the higher-level mediated action (trying to find a restaurant online) builds or provides impetus for the various chains of lower-level mediated actions (the hand movements, gaze shifts or utterances). Thus, neither can be considered as ontologically prior.
Mediated actions are also frozen in the environment and objects within. For our purposes, it is enough to point out the frozen higher-level mediated actions are embedded throughout the interaction which is the focus of analysis herein. Computers have been set up, chairs and desks have been arranged etc. There are a vast number of frozen actions embedded in the material surround but these are not the analytical or empirical focus of the arguments which follow.
In order to analyze human actions and interactions in a systematic and replicable manner, Norris (2004) developed multimodal transcription conventions that are based on the smallest analytical unit, the lower-level mediated action. The transcription process goes through several steps, in which first all lower-level actions related to one mode as performed by each social actor are transcribed separately. This first step is of importance because nonverbal actions are easily overlooked or misinterpreted because as viewers of an audio-video data segment, we see what we believe to see, not necessarily what is actually there. Important to note is that we are transcribing the lower-level mediated actions, not modes. Modes are theoretical concepts, whereas actions are concrete. While actions are what they are, modes can be defined differently by different researchers. But, no matter how you define a mode, if you are using these transcription conventions based on lower-level mediated actions, you will reliably end up with the exact final transcript as any other researcher who is transcribing the interaction. Thus the conventions make the transcription results reliably replicable. The second step in the process is to collate the individual transcripts based on timestamps. During this process, we find overlaps and divergences between lower-level mediated actions and we note them with color-coded arrows and number. As a third step of transcription, we now collate, in our example here, the two individual social actor final transcripts into one overall final transcript. The collation of transcripts again proceeds based on the timestamp in the clip.
Although the transcription process enables a micro analysis of the video, it is not the first step in data analysis. Norris (2019) outlines five phases when working with multimodal data which include data collection, delineating data, selecting data pieces for micro analysis, transcribing data and using analytical tools. Furthermore, data analysis occurs at every phase. During data collection research questions are written and decisions are made about the number of cameras and their placement. Selecting an excerpt of video to transcribe involves delineating mediated actions into higher-level mediated actions relevant to the research question. In transcribing the excerpt of video, first in single mode transcripts and then in collated transcripts, a micro analysis of lower-level actions occurs. The addition of arrows and circles in a transcript highlights the mediated actions and embeds analysis in the transcript. Within MIA, it is after this stage that specific analytical tools, such as modal configuration, for example, can be applied to the data.
As stated earlier, the excerpt of video being transcribed here comes from a study of dyads working on tasks via videoconferencing technology. In total, 12 dyads were recorded completing two tasks, followed by individual interviews. Participants were informed of the task and then placed in separate rooms. They were recorded as they completed the tasks. In order to represent the interaction as closely as possible, multiple cameras were used to capture the full body, the upper body, a webcam to capture the face and screen recording software to capture the online activity. In order to aid in the later synchronizing of video data, the attending research assistant clapped their hands. After data collection, the research assistant collated the different videos into one, using Adobe Premier Pro and then delineated the higher-level actions. This prior analysis enabled the selection of a ‘higher-level action of interest’ which is examined in this article. As we will see below, the transcription process and the resultant transcript show that while each participant co-produces a higher-level action together, the lower-level actions performed by each participant suggests that there are significant differences in the individual higher-level actions being produced.
Here, all lower-level actions related to one mode as performed by each social actor are transcribed separately. Two transcripts are made for each mode depicting participant A (PA) and participant B (PB) individually. The modes examined include: Layout, posture, gesture, object handling, gaze, head movement, facial expression and spoken language. The reading path of the visual transcripts follow Western reading path from left to right. The first image in a row depicts a full body shot of a participant from a side, next, we see an upper body shot of the participants. This is followed by a facial image of the participant (which is the same that the other participant sees on their screen) and the last image depicts a screenshot of the participant’s computer screen. The timestamp in the top left corner helps to depict the duration of the mediated actions and is also used to produce the final collated transcript. It is important to emphasize that timestamps reflect the duration of mediated actions and that some mediated actions take longer to produce, while others take a short time. Individual mediated actions, which are illustrated in the transcripts, do not proceed in a clock-time-bound manner.
Layout is a mode that relates to the space between people, objects and the environment (Norris, 2004, 2019). Image 2 is the layout transcript for PA and PB and it shows the relationship between the computer and computer furniture, and the other participant portrayed in the video depicted on their computer screen. Image 2 shows the frozen mediated actions required to set up the layout for the data collection session. The placement of the computers, task sheets and cameras are previously performed higher-level actions, now frozen within the layout. Due to the number of frozen actions that make up the layout, there is little change in the mode of layout throughout this interaction. The objects, the participants, chairs or the computer screen do not change. The only change in layout occurs when the participants perform lower-level postural shifts and move closer or further away from the computer, but such movements are transcribed in the posture transcript.
Image 2 - Transcribing Layout. Finding La Oliva, 2019
© AUT Multimodal Research Center
The mode of posture includes the positioning and movement of the torso, shoulders and lower body. Postural shifts can include slouching or sitting up straight as well as the crossing of legs or other leg movements. Such postural shifts are bracketed by postural stillness, as postural stillness is bracketed by postural shifts (Norris, 2020). Image 3 is an excerpt from the posture transcript for PA and depicts the participant’s postural stillness.
Image 3 - Transcribing Postural Stillness. Finding La Oliva, 2019
© AUT Multimodal Research Center
Image 4 is an excerpt from the posture transcript for PB and it shows her perform the lower-level action of leaning towards the laptop screen.
Image 4 - Transcribing Postural alterations. Finding La Oliva, 2019
© AUT Multimodal Research Center
The mode of gesture refers to the movement and positioning of fingers, hands and arms during the site of engagement. By defining gesture in this way, self-touch is included as lower-level action of interest (Norris, 2019). Image 5 is the gesture transcript for PA and Image 6 is an excerpt of the gesture transcript for PB.
Image 5 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
Image 5 depicts PA performing a lower-level mediated action as she leans her chin on her hand. In the image 00:03:52:54 she performs a gestural shift as she lowers her finger before resting her chin on her hand again. Image 5 shows that PB performs a lower-level gestural self-touch action at the beginning of the interaction only. Right after the self-touch, she lowers her hand and moves it to the laptop mousepad.
Image 6 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
The mode of object handling relates to the way that objects are used by people. Of course, when handling an object, the person also touches it. Sometimes, depending upon the actions or interactions that we are analyzing, touch is transcribed separately. Here, touch is incorporated in the gesture transcript (as a self-touch) and into the object handling transcript.
Image 7 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
Images 7 and 8 are excerpts of the object handling transcripts for participant A and B. In Image 7 the mode of object handling is visible in the movement of the mouse cursor depicted on the computer screen; and in Image 8, it is visible in the highlighting of the text.
Image 8 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
Here, participant B’s handling of the keyboard is also visible in the transcript.
Gaze direction indicates what or who a person is looking at (Norris, 2004, 2019). This information is visible to the researcher and potentially to other people involved in the interaction. While we cannot determine to what extent a social actor processes the visual information they receive, we can perceive the gaze shifts (Norris, 2020). However, by examining other lower-level actions in connection with gaze shifts, we can often analyze further.
Image 9 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
Image 10 - Transcribing PB’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
When producing a transcript of gaze, it is therefore the gaze shifts performed by the social actor(s) which are collated. Figures 9 and 10 are excerpts from the gaze transcripts for participant A and B and show each of them perform a gaze shift.
The mode of head movement refers to the positioning of the head. There may be (and often is) overlap between the head movement transcript and the transcript for gaze and posture (Norris, 2019). However, by transcribing each mode separately, each mode is given equal scrutiny and moments where for example head movement occurs with or without gaze or postural shifts become visible. Image 11 is an excerpt of the head movement transcript for PA.
Image 11 - Transcribing PA’s Gesture. Finding La Oliva, 2019
© AUT Multimodal Research Center
Image 12, an excerpt from PB’s transcript portrays a modal aggregate of a head movement performed with a gaze and postural shift as she leans closer to the screen.
Image 12 - Transcribing Head Movement for PB. Finding La Oliva, 2019
© AUT Multimodal Research Center
This subtle head movement is particularly visible in the face shot, demonstrating that various camera angles are very useful when examining actions and interactions.
Facial expressions refer to the movement or stillness of a person’s face. Therefore, when creating a facial expression transcript a capture is taken from the beginning and end of a change in a social actor’s expression (Norris, 2020). Images 13 and 14 are the facial expression transcripts for participant A and B and they illustrate some facial expressions performed by each participant.
Image 13 - Transcribing Facial Expression for PA. Finding La Oliva, 2019
© AUT Multimodal Research Center
Image 14 - Transcribing Facial Expression for PA. Finding La Oliva, 2019
© AUT Multimodal Research Center
There are two transcripts created when transcribing spoken language. The first, we transcribe spoken language, using Tannen’s (1984) transcription conventions as illustrate in the Verbal Transcript.
| (1) | A: | I quite like this |
| (2) | ahm | |
| (3) | French cuisine | |
| (4) | ah | |
| (5) | La Oliva | |
| (6) | do you see it, | |
| (7) | it’s a restaurant | |
| (8) | I do have a look at | |
| (9) | time when it’s open, | |
| (10) | ahm | |
| (11) | B: | n |
| (12) | uhuh |
Here, according to the conventions, the participants overlap their spoken language is indicated in lines (10) and (11).
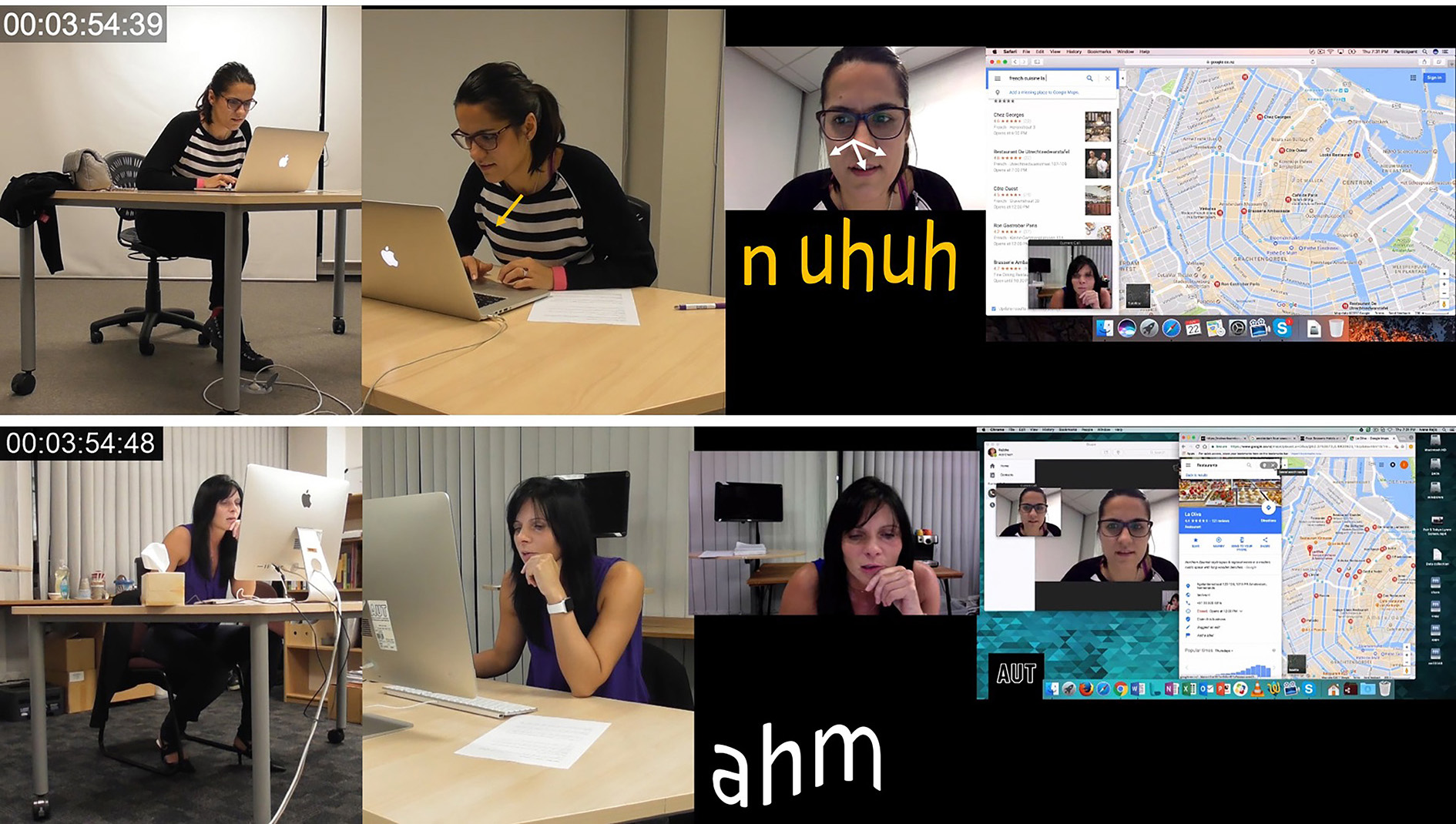
Second, we utilize our multimodal conventions, overlaying the spoken language over the image transcript, thereby visualizing prosodic features through use of font size, shape and spaces. This is done when the final transcripts are produced. Image 14 depicts an excerpt of the final transcript in which all modes, including the multimodal transcript of the spoken language, are depicted.
Image 15 - Transcribing Facial Expression for PA. Finding La Oliva, 2019
© AUT Multimodal Research Center
Here, spoken language is visualized and overlaid over the images, depicting not only what is said, but also the intonation pattern that the speaker uses as well as the pauses between the utterances. Speaker utterances are color-coded and placed close to the speaker so that the reader knows which speaker says what. Further, since the reading path of the transcript is from left to right, we can see that PB (top row) begins to speak at the very same time as PA (bottom row).
Participants A and B collaboratively produce the higher-level action of determining a suitable restaurant to eat at while they will be in Amsterdam on an imagined business trip. They do so through multimodal ensembles of non-verbal and verbal lower-level actions which occur in the communicative modes of posture, proxemics, gaze, head movement, hand movement, gesture, object handling and spoken language. While they co-produce this higher-level action together interactionally, analysis of the lower-level actions undertaken by each participant suggests that there are considerable differences in the individual higher-level actions being produced. In other words, through co-producing the higher-level action of determining a suitable dining location, each participant simultaneously produces their own higher-level action, independent of the interlocuter. PA produces the higher-level action of suggesting a restaurant and PB produces the higher-level action of searching for the suggested restaurant.
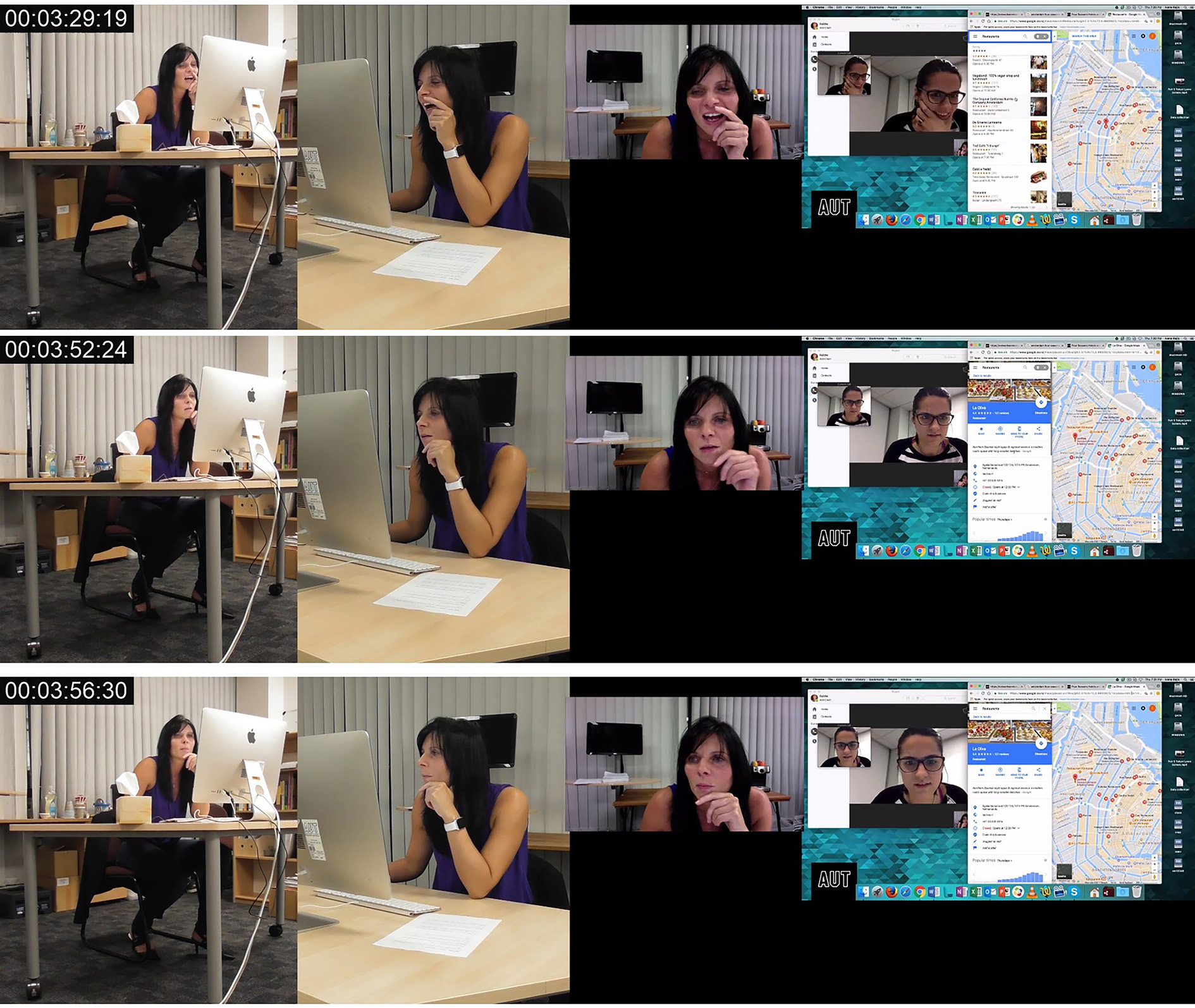
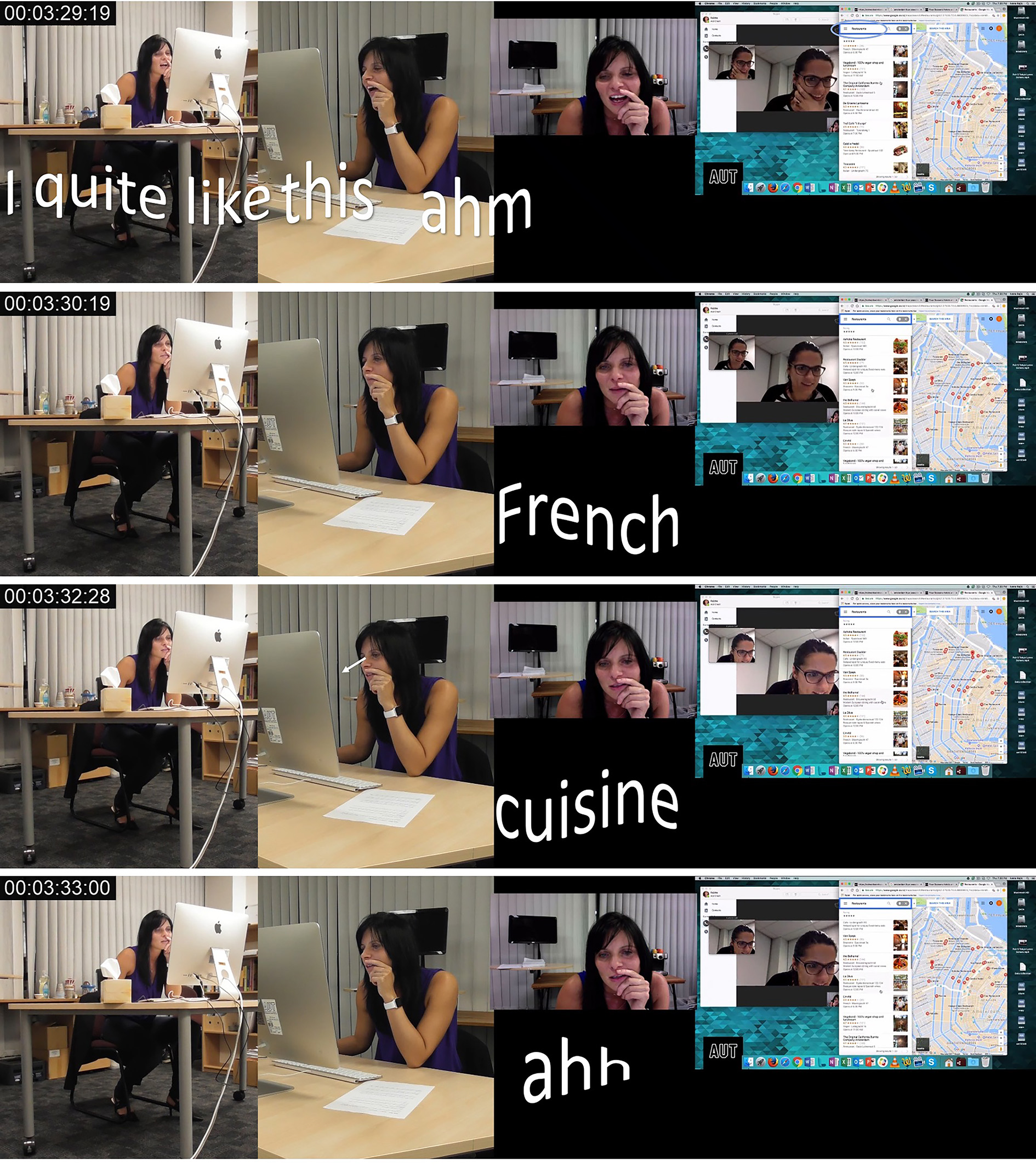
In Image 16, PA initiates the higher-level action through multiple lower-level actions undertaken through the modes of gaze, posture, spoken language and object handling.
Image 16 - PA Initiates a Higher-Level Action. Finding La Oliva, 2019
© AUT Multimodal Research Center
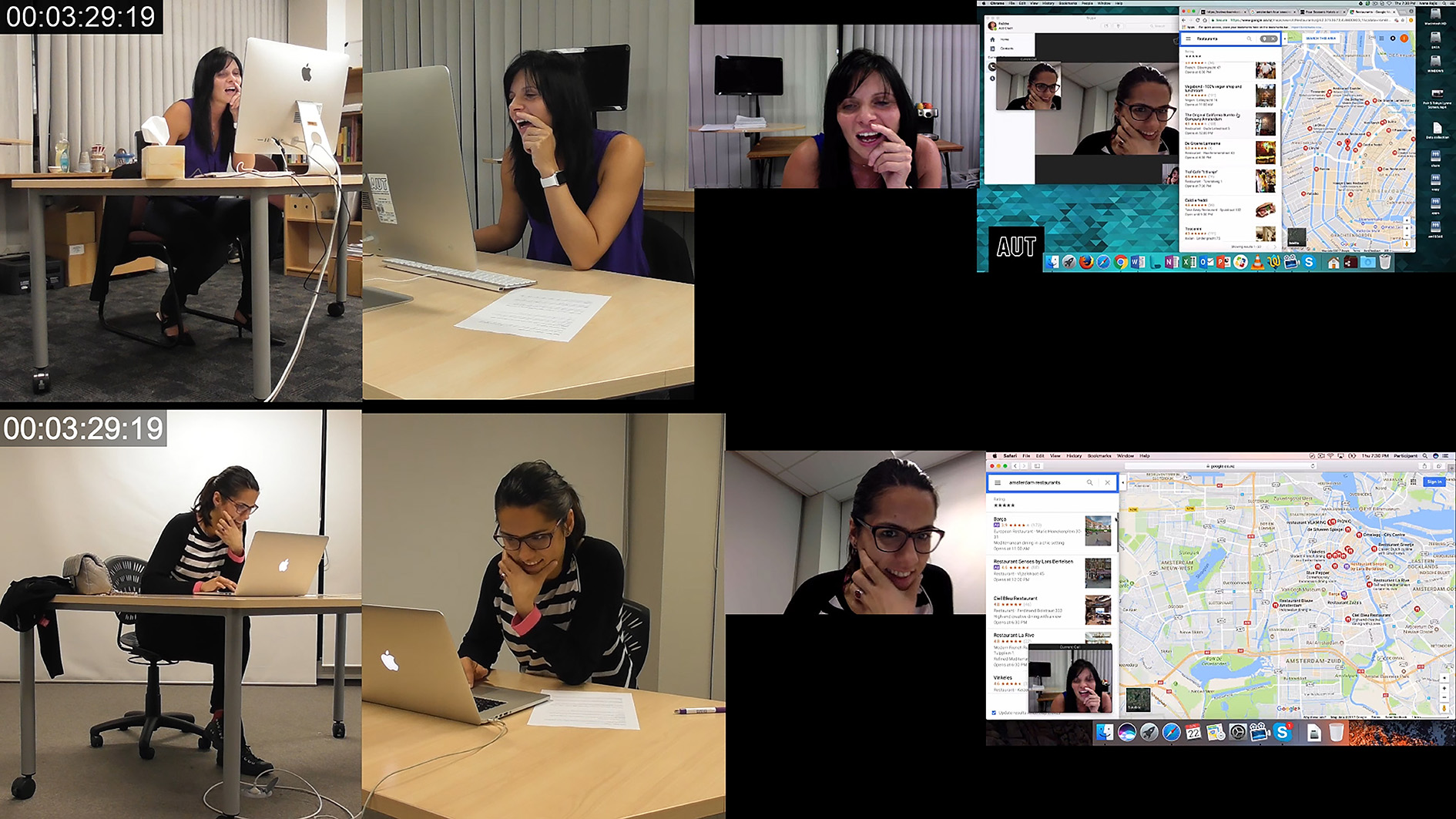
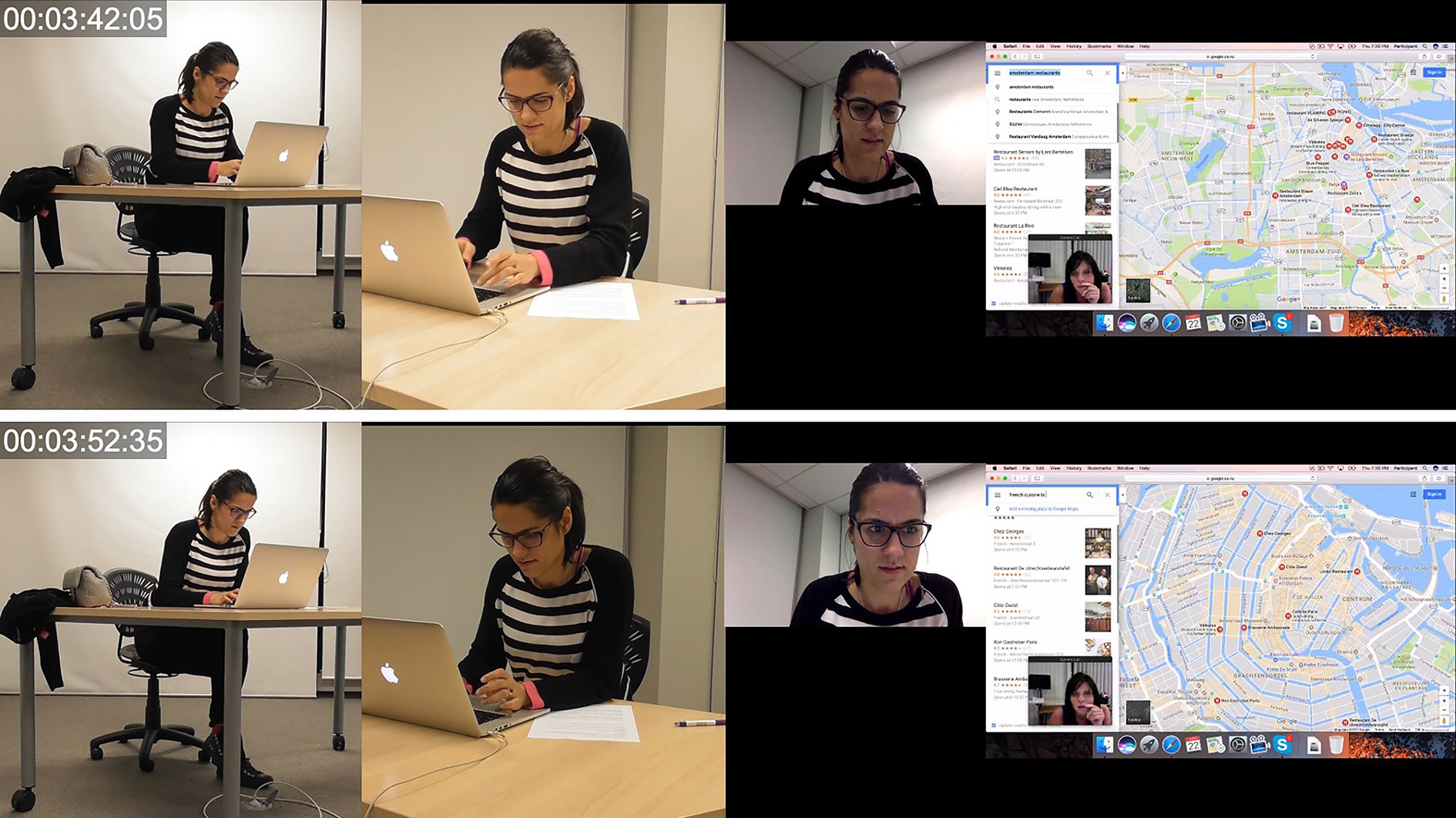
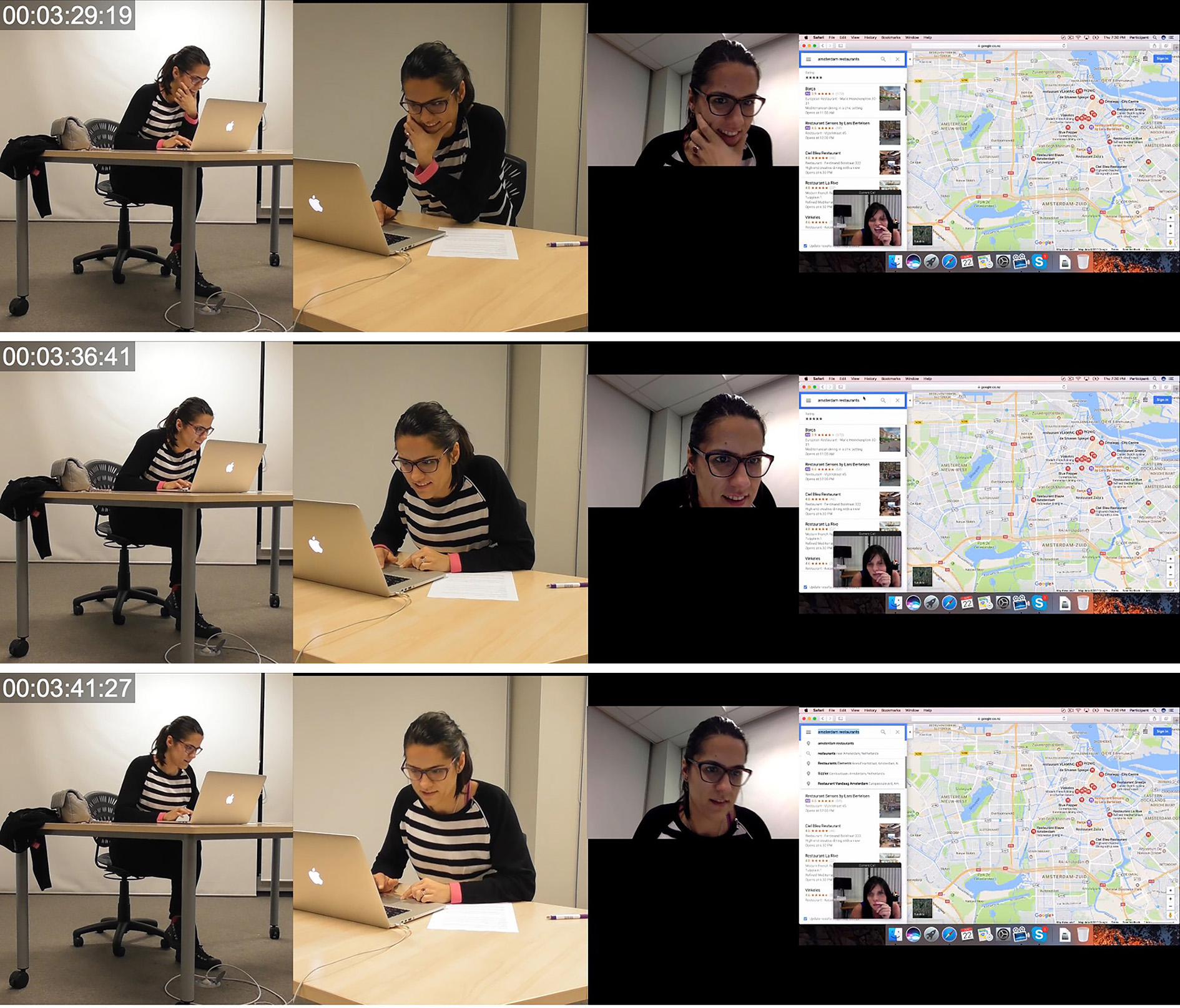
At 3:29:19, through mode of spoken language, PA says “I quite like this ahm French cuisine ah La Oliva do you see it” indicating both her interest in this place while simultaneously presenting this as a viable option to her interlocutor. Simultaneously, following the word ‘quite’ PA undertakes multiple lower-level actions through the mode of object handling as she begins scrolling through a dropdown list of restaurants in the city center of Amsterdam. While the lower-level action is not explicitly visible itself, from 3:29:19 to the final frame at 3:33:00, the composition of the dropdown menu showing various restaurants can be seen changing. Additionally, in each frame, a different location pin on the map is enlarged indicating that the mouse cursor was hovering on a different restaurant in the dropdown menu at each time interval. As Geenen (2017) argues, mediated actions can be very precisely inferred analytically by virtue of mediational residue which refers to the material results of mediated action. The lower-level action of object handling and more specifically using the mouse tracker to scroll while moving the cursor itself and be inferred from the visual alterations on screen.
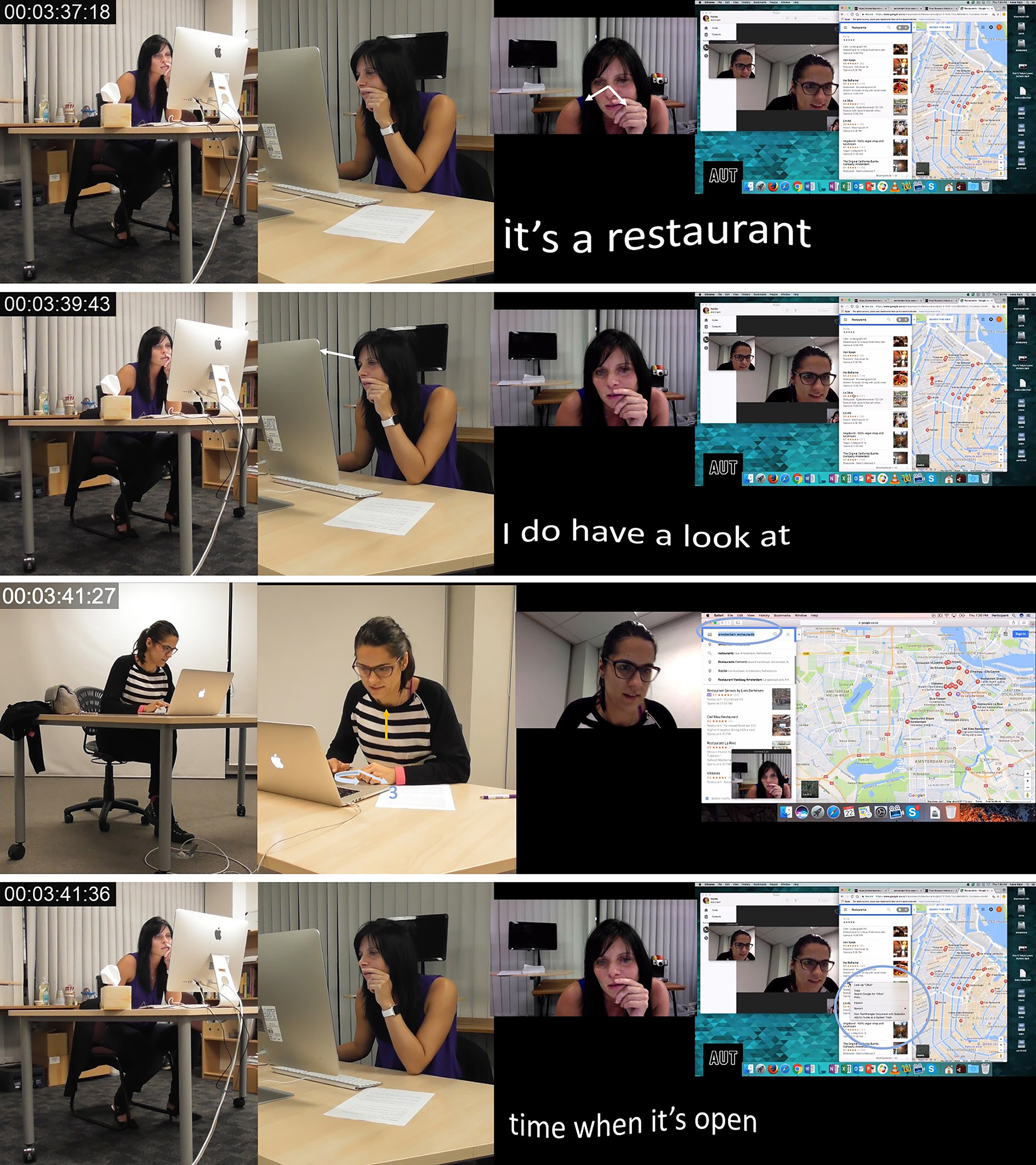
As shown in Image 17, at 3:34:46, PA additionally asks through the mode of verbal language “do you see it” followed by an explanation that “it’s a restaurant” and an indication that she will look at the opening hours. Simultaneously, PA performs multiple other lower-level actions through the modes of gaze and object handling most saliently.
Image 17 - PA Selects a Restaurant. Finding La Oliva, 2019
© AUT Multimodal Research Center
At the onset of pronominal reference in the interrogative, PA alters gaze back and forth between the left and right side of the computer screen. Most plausibly, these lower-level actions through the mode of gaze are a form of non-verbal confirmation checks and gaze direction alters between the google dropdown menu featuring restaurants and her interlocutor. Further evidence for the gaze alterations being both directed between the interlocutor and the dropdown menu and functioning as confirmation checks is provided by virtue of the lack of verbal response to both the initial proposition and additional interrogative. Participant B (PB) does however, perform a number of lower-level mediated actions during this interactional segment only they do not occur through the mode of spoken language.
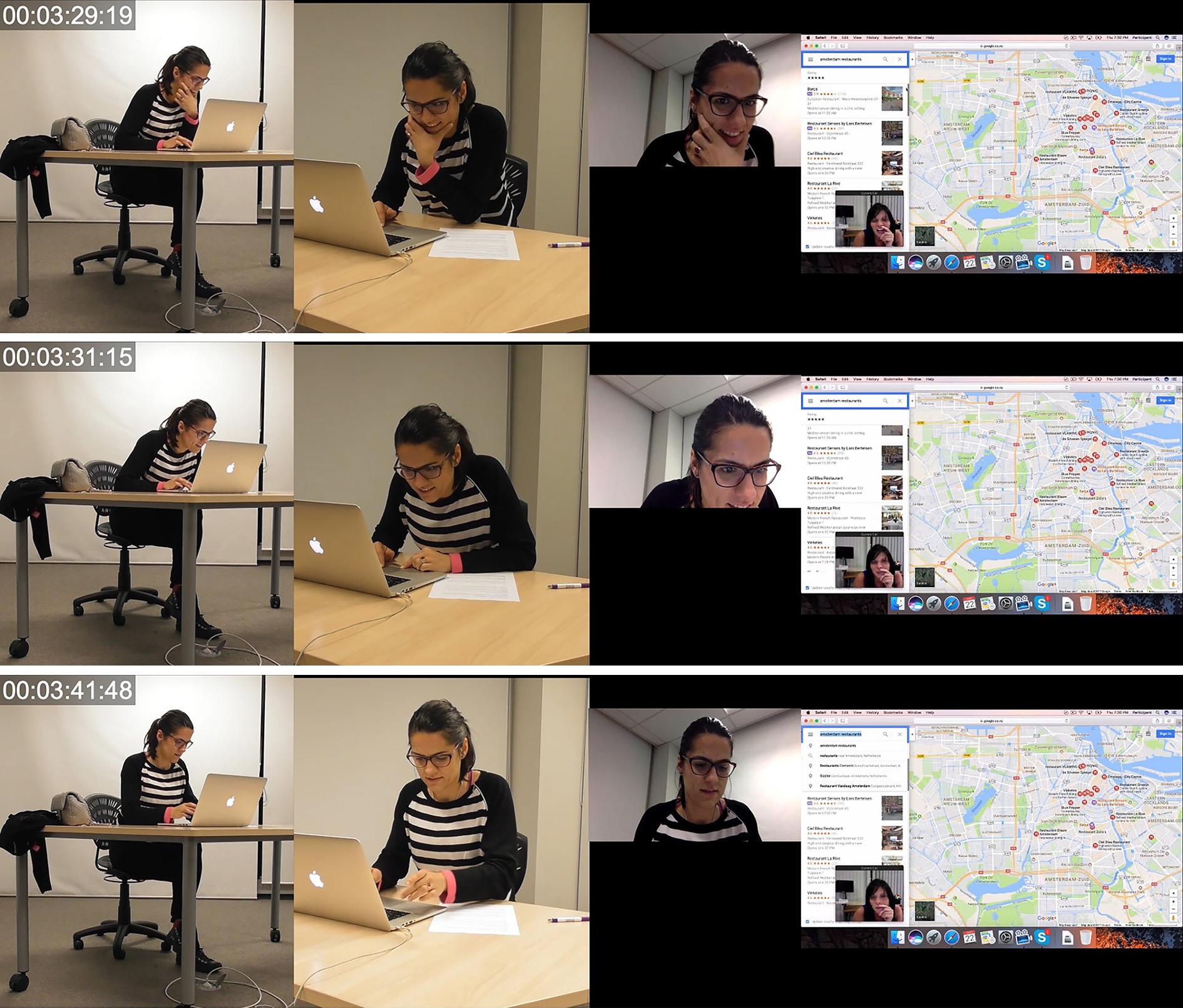
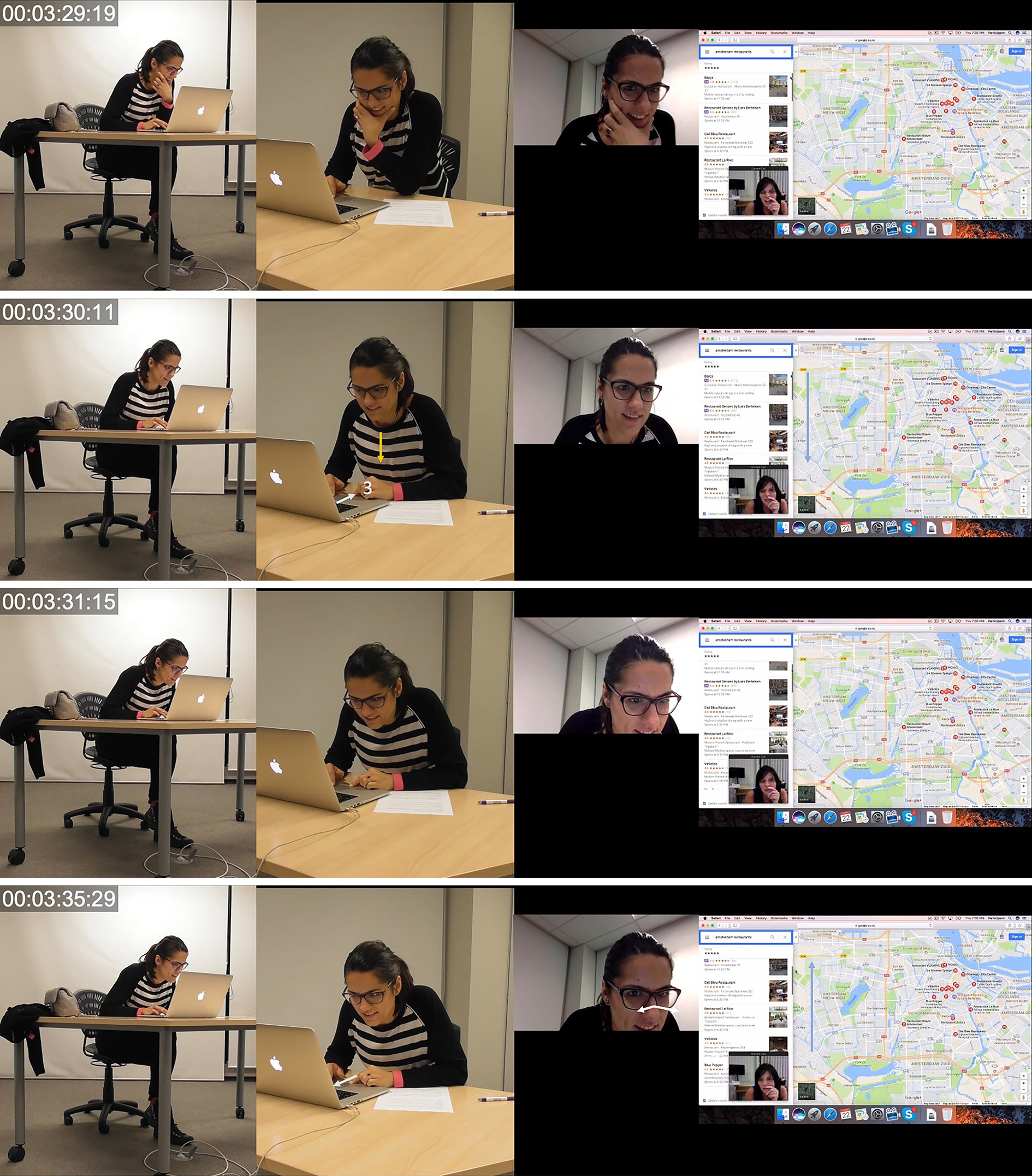
In Image 18, between 3:29:19 and 3:35:29 when PA initiates her proposition “I quite like”, PB undertakes multiple lower-level actions involving hand movement, posture, object handling and gaze.
Image 18 - PB Searching for Restaurant. Finding La Oliva, 2019
© AUT Multimodal Research Center
First, PB’s hand moves from its position cupping the chin in concentration or consideration moving down to rest on the body of the laptop with her index finger located on the trackpad. Immediately following the hand movement, multiple other lower-level actions through object handling and posture occur. At 3:30:11, PB performs a postural shift whereby she drops the upper portion of her torso including the head and shoulders downward and slightly forward. This also occurs with an intensification of gaze. PB then begins scrolling through the google dropdown menu on her screen. The direction of scroll is indicated by small arrows located beside the dropdown menu. Additionally, the cursor can be seen located on top of the scroll bar at the right-hand side of the dropdown menu. As mentioned before, the mediational residue of the cursor location coupled with the precise hand position including an extended index on the cursor pad suggests that PB also clicked and held down on the cursor pad during the duration of the scrolling. Lower-level actions through object handling additionally occur with two fingers of PB’s right hand as she scrolls. Scrolling can be seen to occur with short up and down drags on the righthand side of the cursor pad while her left-hand holds pressure on the pad.
Image 19 - PB Typing Restaurant Name. Finding La Oliva, 2019
© AUT Multimodal Research Center
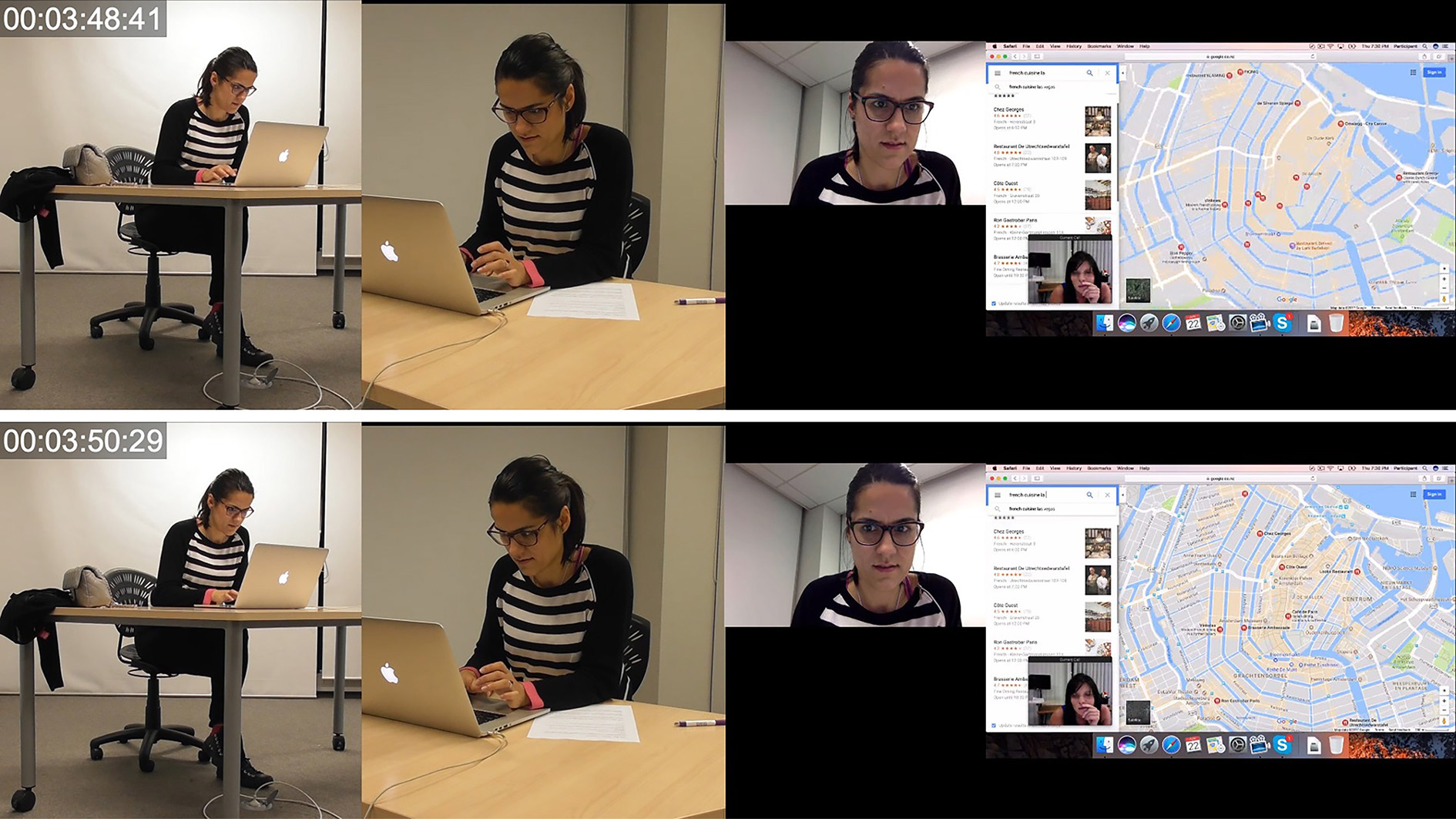
In Image 19 at 3:41:27, PB again undertakes lower-level actions through posture, gaze and object handling wherein she sits up slightly which is temporally coordinated with the cessation of the gaze intensification which occurred during the actions of scrolling. Simultaneously, lower-level actions through object handling occur as the current text in the search field at the top of the dropdown menu showing restaurants is highlighted. After the postural alteration occurs, PB begins audibly typing in the search field and these multiple lower-level actions that realize the typing end after she has written “French Cuisine La” at which point and automatically generated google suggestion appears below and PB clicks on the suggestion. This results in the surface area of the map being minimized as the map area focuses on a smaller area no longer including the New West and Old South but honing in on the immediate city center, including the Jordaan and a small section of the east. Additionally, throughout this segment of interaction PB’s gaze, when not intensified during scrolling, has been oscillating back and forth and to different locations on the screen. Conceivably, the oscillation is occurring between the multiple dialogue boxes on screen which feature the map, the connected dropdown menu with search field at the top and a view of PA in the lower left-hand corner. While a vast diversity of lower-level mediated actions are undertaken in the 27-second segment, the only vocalization which PB undertakes is the non-lexical negation of ‘n uhuh’ occurring at 3:54:39, approximately 20 seconds after the initial proposition, identification of name and interrogative from PA.
During this short segment of videoconferencing interaction, PA appears to be actively engaged in the higher-level action of choosing a restaurant while PB does not. PA makes assertions and propositions in attempting to determine a suitable dining location, verbally articulates courses of actions like checking opening hours and even poses explicit interrogatives to her interlocutor, simultaneously producing the higher-level action of choosing a restaurant and suggesting a restaurant. During this time PB does not provide a single verbal response or backchannelling cue to indicate some degree of attention and awareness to the interaction itself. An analysis of the spoken verbiage would lead the analyst to conclude that PB has potentially opted out of the interaction (Grice, 1975), choosing not to engage in the conversation at all. The aversion of gaze toward their interlocutor, oscillating gaze shifts and postural alterations complemented by object handling and gaze intensifications toward particular dialogue boxes could suggest complete disengagement in the current course of interaction. However, an analysis of lower-level mediated actions instead of just language use in interaction reveals that the non-verbal actions are crucially relevant to both the ongoing interaction and the collaborative task at hand. PB is producing the higher-level action of searching for the suggested restaurant and therefore co-producing the higher-level action of choosing a restaurant. Image 20 shows the entire higher-level action transcript for both interlocutors.
Image 20 - Full Transcript of Finding La Oliva, Finding La Oliva, 2019
© AUT Multimodal Research Center
The non-verbal actions undertaken by PB indicate that the co-produced higher-level action of finding a suitable dining location in Amsterdam is in the foreground of her attention and awareness. Gaze intensification, postural alterations, gaze oscillation and object handling contribute to the production of modal density through modal complexity (Norris 2004, 2019, 2020). All of the actions performed are oriented toward the dropdown menu of restaurants and the search box on top. In other words, the actions are contributing to ‘finding’ La Oliva, the restaurant which was mentioned by PA in her proposition. While the higher-level action of determining a suitable location to dine is being co-produced at this site of engagement, the actual higher-level actions that PA and PB perform vastly differ. The flux and flow of convergence and divergence during this interaction can shed light on some particularities about the material and communicative structure of videoconferencing mediated collaborative tasks.
Throughout this segment of interaction, the participants are currently searching for a suitable dining establishment in Amsterdam. While co-producing the same higher-level action, they often diverge in their immediate focus, producing vastly different individual actions. While discourse analysts and conversation analysts have traditionally approached the notion of attention as unproblematic and typically used linguistic behavior as indicative of attention, Norris (2004, 2011, 2019, 2020) argues that focused attention is not always directly indicated by language use and additionally, that crossing micro and macro analytical boundaries is paramount in determining the distribution of focused attention.
Teasing apart the points at which the social actors converge and diverge may provide further insights into the dynamics of task orientation, attention, focus and collaborative teamwork while videoconferencing. Additionally, degrees of divergence and convergence coupled with how the intersections manifest and attentional orientations change could be explicitly telling of the interactional and cognitive complexities of coordinated collaborative activity.
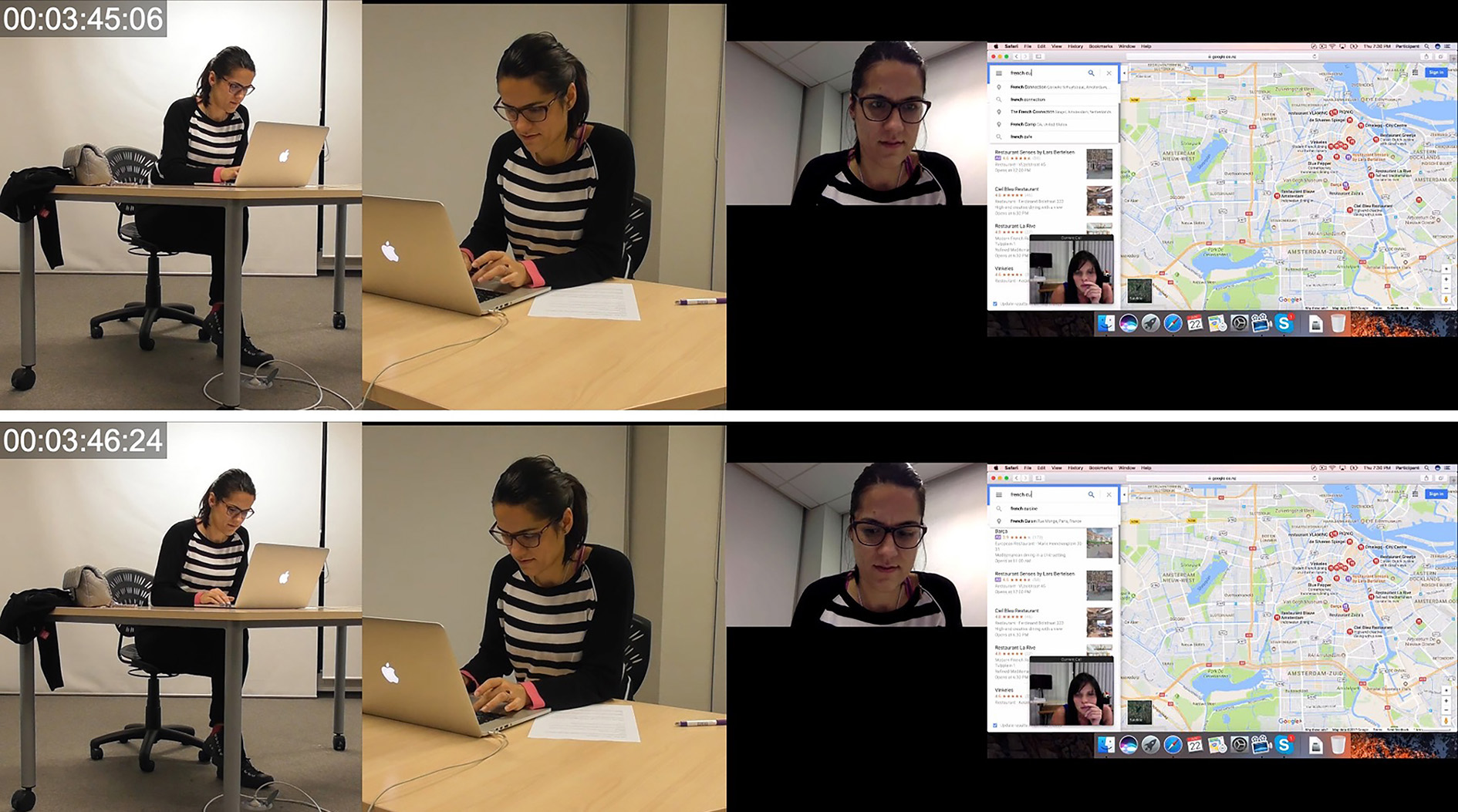
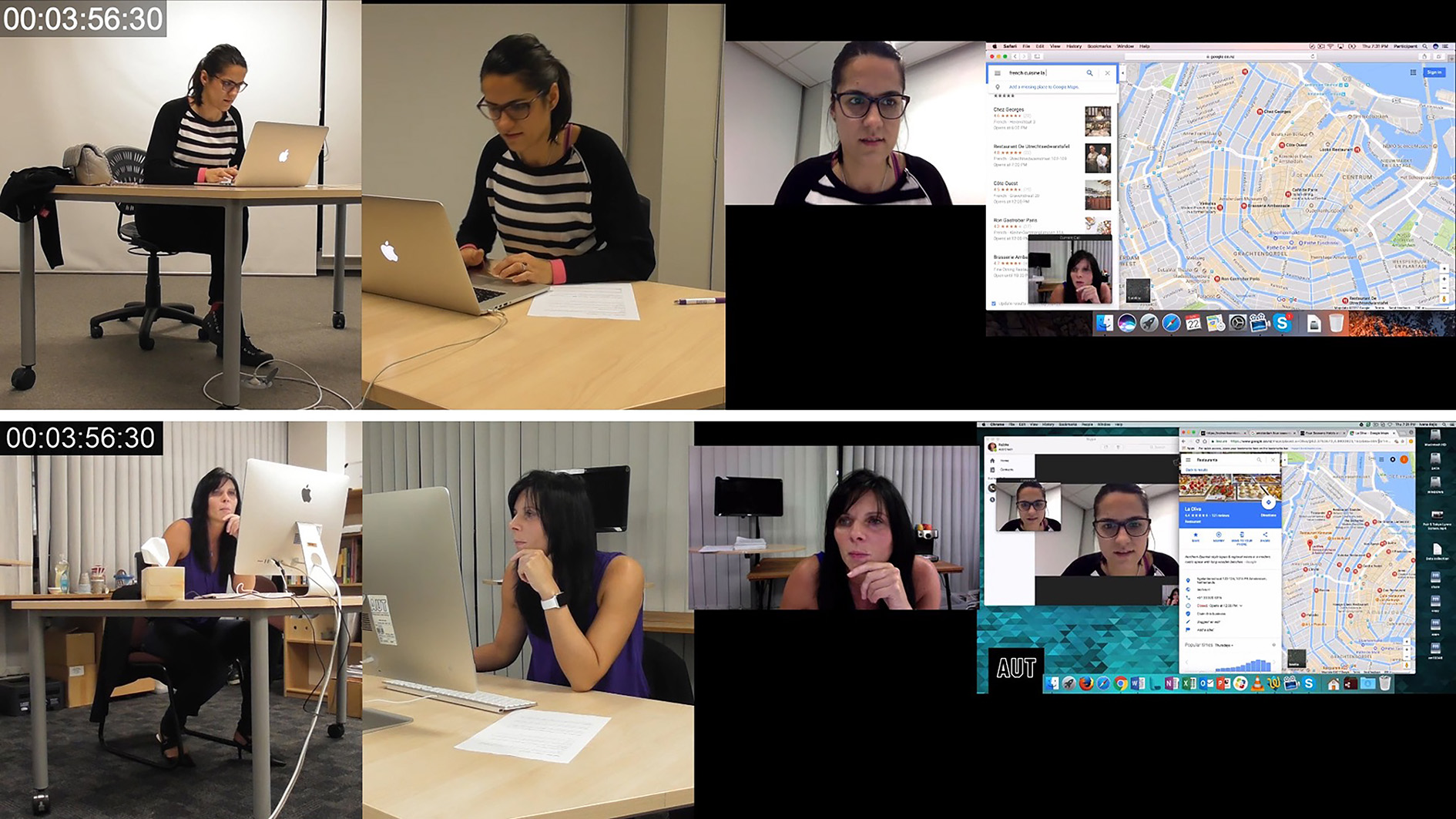
During the first 7 seconds of the segment of videoconferencing interaction, PA undertakes multiple lower-level actions through various non-verbal and verbal modes of communication. Through the mode of spoken language she says, “I quite like this ahm French cuisine ah La Oliva do you see it”. While speaking, PA is simultaneously scrolling through a google maps dropdown menu of search items which have been returned while looking for a restaurant. In Image 18 at 3:33:21 she begins realizing the spoken utterance but also initiates multiple lower-level actions through the mode of object handling. She scrolls up through the dropdown menu list twice, in quick succession and then scrolls down once. After scrolling down, PA repositions the cursor traveling over multiple results in the dropdown menu and stops at one item which is situated in the middle of the frame. The cursor comes to a stop over one selection just prior to PA saying, ‘La Oliva’. The coordination of the resting cursor, the non-lexical vocalization ‘aha’ and the temporal and rhythmic stagnation which occurs just prior to saying ‘La Oliva’ suggests that PA was searching for a particular result which seemed promising but had not remembered the exact name. Once located, PA can finish the proposition which was initiated at 3:33:21.
As detailed in the previous section, at the same time, PB is undertaking various lower-level actions but most pertinent to discuss here are those in the mode of object handling. PB is also scrolling through the dropdown menu displaying the search results in google. While PB is not speaking, the lower-level action taken by both social actors appears to converge as they are both searching for a restaurant and employing object handling and multiple other technological tools to do so. Here, the lower-level mediated actions converge as both social actors are engaged in congruent material practices.
At 3:35:29, immediately after PA says the name ‘La Oliva’, PB undertakes multiple lower-level actions through the modes of gaze and object handling. Immediately after the realization of the restaurant name, PB scrolls in the opposite direction at a very fast pace. At the same time, her gaze alters quickly three times, back and forth from different sides of the screen. It appears as though PB, upon hearing the mention of a specific place and realizing that this has not been featured in the dropdown list she is currently viewing, scrolls to the top of the list while completing a final look at the absence of La Olive in her search results. This can be deduced from the lower-level actions which immediately follow wherein she explicitly searches for the precise lexical string articulated by PA: French cuisine La.
While PB has slightly altered her orientation to the task and is now attempting to locate ‘La Oliva’. PA has also changed her task orientation and instead of looking for a suitable option from the search results, PA is now exploring the potential of a single restaurant. PA undertakes multiple lower-level actions through the mode of object handling wherein she attempts to get more information about La Oliva to further assess its suitability. PA articulates this in spoken language appearing to talk through her process of consideration, perhaps to provide her interlocutor with an understanding of what aspects of the location are pertinent.
As seen in Image 20 at 3:45:02, PA expands the search result whereby La Oliva and information pertaining to operating hours, peak times, contact info etc. is visible in the same screen space as the previous dropdown menu search results. Immediately after locating La Oliva and asking PB “do you see it?” PA undertakes multiple lower-level actions through object handling and spoken language which indicate that her attention is directed toward more conscious consideration of a specific restaurant to see if it meets criteria to warrant being suitable. PA vocalizes certain components of consideration criteria, articulating her own actions prior to their occurrence and expands the search result item to access more information about the place. The lower-level actions taken here suggest that careful consideration or more intended consideration is at the forefront of her attention and awareness.
However, at this time PB’s lower-level actions and accompanied task orientation differ considerably. With gaze intensely allocated to the screen and with closed proxemic distance between herself and the screen, PB scrolls quickly through her search results to learn that La Oliva is not there. Immediately following, PB highlights the text which is currently present in the search field. As soon as all the text is highlighted, PB initiates a postural shift altering the position of her head, neck and torso to a more upright position. This alters the proxemics between herself and the computer and results in a positioning that is more upright than the previous with less intensity of gaze. It appears as though this alteration is completed in preparation for typing as PB begins more lower-level actions in the form of typing as soon as her postural shift ends. PB types ‘french cu’ and prior to being able to finish, an automatically generated suggestion ‘french cuisine’ appears immediately below the search box. After selecting the suggestion, PB continues to type, include ‘la’ after the automatically generated suggestion. Immediately following the selection of the auto text provided by google and as PB begins to type ‘la’ the map automatically zooms in. PB undertakes multiple gaze alterations, momentarily directing gaze at the keyboard and then back to the screen. At 3:50:23, after the map which includes location pins has enlarged, PB redirects and intensifies gaze toward the map while also closing the proxemic distance between herself and the computer. This is accompanied with a postural shift with her torso moving forward and downward. Following this, PB undertakes a lower-level mediated action through spoken language saying ‘n uhuh’ which indicates that she has failed to locate La Oliva.
From 3:35:29 to 3:54:39 the lower-level actions undertaken by PB predominantly involve various postural alterations, gaze alterations and oscillations and object handling. PB appears to not provide any verbal response to her interlocutor who has made a proposal, asked a question and articulated features of further consideration in announcing upcoming actions. Normally, this would be considered sanctionable interactive behaviour. The temporal gap between the actual interrogative and the final negative far exceeds what would be considered acceptable or normal in face-to-face conversation. It is demonstrably clear that PA and PB diverge substantially not only in the material nature of their lower-level actions but also in their immediate attentional orientation. PA is making a proposal and further considering a potential option while PB is trying to locate La Oliva first in her existing search results, then on the map and again in the dropdown menu. PB does not even provide any material indication that she has heard PA’s proposal or question. Their communicative actions diverge so dramatically that without access to screen behavior and the mediational residue of PB’s action coupled with visual transcription, it would appear as though PB has indeed opted out of the interaction.
Above, we have reiterated arguments in favor for the use of visual transcription methods, advocated a way how it can be done and briefly detailed this method. We have argued that during a collaborative task that involves restaurant selection on an imagined business trip, two social actors co-produce collectively a higher-level mediated action identifiable as determining a suitable dining location while in Amsterdam. However, their individual higher-level actions differ quite dramatically. We have additionally argued that the lower-level actions undertaken by interlocutors fluctuate in the degrees to which they converge and diverge. In other words, when team members or collaborators are doing the same thing, they are not necessarily always doing the same thing. This may have ramifications for our understanding of collaborative activity, teamwork and technologically mediated interactions more generally.
The increasingly multimodal orientation of the language and communication sciences creates a methodological exigency wherein visual transcription methods will most likely become more commonplace. The widespread use of audio-video tools for data generation and the analytical focus on the significance of non-verbal communicative action requires a transcription protocol that is greater than a transduced version of textual description for phenomenon which is non-verbal. Visual forms of transcription facilitate a more precise understanding of the material nature of unfolding interactive phenomena upon which analysis and arguments regarding communicative or pragmatic function are more firmly grounded. While Bezemer and Mavers (2011) point out, “the ‘accuracy’ of a transcript is dependent not on the degree to which it is a ‘replica’ of reality, but how it facilitates a particular professional vision” (p. 196), we would like to argue that when an aspect of one’s professional vision involves the contention that all human communication is multimodal by nature, visual transcription methods are an empirical necessity. Visual transcription facilitates an analytical orientation prioritizing all forms of communicative action simultaneously whether these occur via spoken language, gesture, posture or even the use of objects. Furthermore, MIA’s multimodal transcription conventions allow us to show what is actually happening in an interaction in a reliable and replicable manner, whether produced by the researchers themselves or by trained research assistants.
AGUILA Almond (2012), “Time and Space on Skype: Families Experience Togetherness While Apart”, Explorations in Media Ecology, 10 (3-4), p. 303-312.
BEZEMER Jeff, MAVERS Diane, (2011), “Multimodal Transcription as Academic Practice: A Social Semiotic Perspective”, International Journal of Social Research Methodology, 14 (3), p. 191-206.
BOLDEN Galina (2003), “Multiple Modalities in Collaborative Turn Sequences”, Gesture, 3 (2), p. 187-212.
BUCHOLTZ Mary (2000), “The Politics of Transcription”, Journal of Pragmatics, 32 (10), p. 1439-1465.
GEENEN Jarret (2017), “Show (and Sometimes) Tell: Identity Construction and the Affordances of Video‐Conferencing”, Multimodal Communication, 6 (1), p. 1-18.
GEENEN Jarret (2018), “Multimodal Acquisition of Interactive Aptitudes: A Microgenetic Case Study”, Pragmatics & Society, 9 (4), p. 518-544.
GEENEN Jarret, PIRINI Jesse (2020), “Multimodal (Inter)action Analysis”, in MCKINLEY Jim, ROSE Heath (eds.), The Routledge Handbook of Research Methods in Applied Linguistics, New York, Routledge, p. 488-499.
GOODWIN Charles (1994), “Professional Vision”, American Anthropologist, 96 (3), p. 606–633.
GREEN Judith, FRANQUIZ Maria, DIXON Carol (1997), “The Myth of the Objective Transcript: Transcribing as a Situated Act”, TESOL Quarterly, 31 (1), p. 172-176.
Grice, H. Paul. 1975. Logic and conversation. In Syntax and Semantics, Vol. 3: Speech acts ed. By P. Cole & J. L. Morgan. New York: Academic Press.
HEPBURN Alexa, BOLDEN Galina (2012), “The Conversation Analytic Approach to Transcription”, in SIDNELL Jack, STIVERS Tanya (eds.), The Handbook of Conversation Analysis, Chichester, Wiley-Blackwell, p. 57-76.
HERITAGE John (2012), “The Epistemic Engine: Sequence Organization and Territories of Knowledge”, Research on Language and Social Interaction, 45 (1), p. 30-52.
HOLMES Janet, MARRA Meredith (2004), “Leadership and Managing Conflict in Meetings”, Pragmatics, 14 (4), p. 439-462.
Jefferson, G. (1984) Notes on a systematic deployment of the acknowledgment tokens “yeah” and “mm hm”. Papers in Linguistics 17: 197-216.
MARRA Meredith (2012), “Disagreeing without Being Disagreeable: Negotiating Workplace Communities as an Outsider”, Journal of Pragmatics, 44 (12), p. 1580-1590.
MILLER Elizabeth (2018), “Interaction Analysis”, in PLONSKY Luke, PHAKITI Aek, STARFIELD Sue, DE COSTA Peter (eds.), The Palgrave Handbook of Applied Linguistics Research Methodology, London, Palgrave Macmillan, p. 615-638.
MONDALA Lorenza (2012), “The Conversation Analytic Approach to Data Collection”, in SIDNELL Jack, STIVERS Tanya (eds.), The Handbook of Conversation Analysis, Chichester, Wiley-Blackwell, p. 32-56.
MOREK Morek (2015), “Show That You know – Explanations, Interactional Identities and Epistemic Stance-Taking in Family Talk and Peer Talk”, Linguistics and Education, 31, p. 238-259.
NORRIS Sigrid (2004), Analysing Multimodal Interaction: A Methodological Framework, London, Routledge.
NORRIS Sigrid (2011), Identity in (Inter)action: Introducing Multimodal (Inter)action Analysis, Berlin-Boston, Mouton.
NORRIS Sigrid (2013), “What Is a Mode? Smell, Olfactory Perception, and the Notion of Mode in Multimodal Mediated Theory”, Multimodal Communication, 2 (2), p. 155-170.
NORRIS Sigrid (2019), Systematically Working with Multimodal Data: Research Methods in Multimodal Discourse Analysis, Hoboken, Wiley-Blackwell.
NORRIS Sigrid (2020), Multimodal Theory and Methodology: For the Analysis of (Inter)action and Identity, New York, Routledge.
NORRIS Sigrid, PIRINI Jesse (2016), “Communicating Knowledge, Getting Attention, and Negotiating Disagreement via Videoconferencing Technology: a Multimodal Analysis”, Journal of Organizational Knowledge Communication, 3 (1), p. 23-48.
SCOLLON Ronald (1998), Mediated Discourse as Social Interaction: A Study of News Discourse, London, Longman.
SCOLLON Ronald (2001), Mediated Discourse: The Nexus of Practice, London, Routledge.
SIDNELL Jack (2012), “Basic conversation analytic methods”, in SIDNELL Jack, STIVERS Tanya (eds.), The Handbook of Conversation Analysis, Chichester, Wiley-Blackwell, p. 77-99.
Tannen, D. (1984), Conversational Style: Analyzing Talk among Friends. Norwood, N.J.: Ablex.
WERTSCH James (1998), Mind as Action, New York, Oxford University Press.
Jarret Geenen, Tui Matelau-Doherty, Sigrid Norris, « Visual transcription. A method to analyze the visual and visualize the audible in interaction », Revue française des méthodes visuelles [En ligne], 5 | 2021, mis en ligne le 9 juin 2021, consulté le . URL : https://rfmv.fr